I might be wrong to assume that almost everyone working with Google Tag Manager, Piwik Pro, or Tealium TMS has some familiarity with dataLayers and has worked with them before.
However, this article does not explain what a dataLayer is or how to create one.
Instead, it focuses on governance strategies, necessary checks and best practices (I feel that eye roll) that are often overlooked when setting up a dataLayer for your clients or business.
Many people associate dataLayer governance solely with documentation. While documentation is crucial, governance extends far beyond that.
This is why I’ll highlight key governance strategies you might not be aware of in this article, but first, let’s see why it’s essential to have dataLayer governance in place.
Why Is DataLayer Governance Important?
Proper governance of your dataLayer code and its execution is essential for preventing:
- Measurement failures
- Tracking complexities
- Confusion in implementation
- Data quality issues
…and much more.
So, what governance principles should you follow when creating, using, managing, and implementing a dataLayer?
DataLayer Governance Best Practices
Here are the crucial areas I’ll cover in this article:
- Proper documentation of your dataLayer setup
- Adopting an internal naming convention (e.g., a recognized prefix for event names)
- Ensuring every dataLayer push includes an event name
- Use the Right Tools for Sharing DataLayer Code
- Initializing the dataLayer correctly, especially for page-load events
- Maintaining consistency in structure, key names, and values
- Regularly reviewing and auditing your dataLayer setup
- Properly grouping related data for better organization
- Conducting QA testing before deployment
- Ongoing monitoring: don’t set it and forget it!
- Automating DataLayer code generation
- Keep an eye on DataLayer Bloat
- Vendor specifications still matter
Let’s take a detailed look at each of the items mentioned above.
Proper Documentation of Your DataLayer Setup
Documentation is one of the most well-known aspects of dataLayer governance, yet it is rarely implemented consistently across teams.
Having comprehensive documentation of your dataLayer setup is essential. It provides clear dataLayer specification, and a centralized reference for collaborators or future team members, allowing them to understand what dataLayers exist, their measurement purpose, business use case, and how they are executed.
A simple spreadsheet is a great starting point, like the example here. This can include:
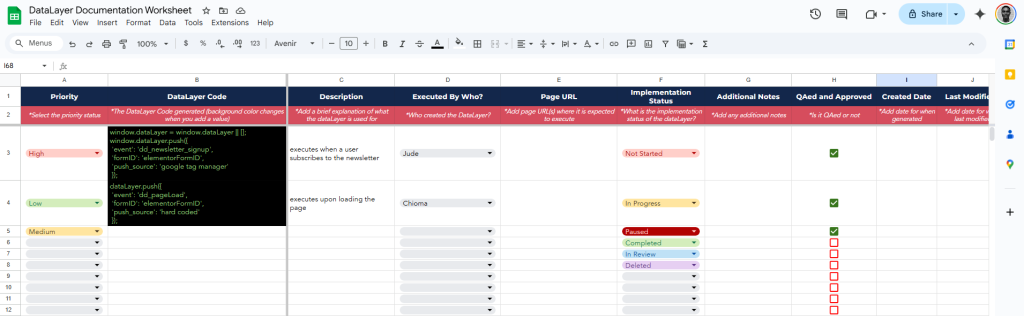
- The dataLayer code
- Where it is executed
- Who implemented it
- Implementation status
- Additional notes or context
This documentation can fit in your analytics project whether you are in the planning stage or have already completed an implementation.
It also serves as an internal business document that should be shared within your organization.
However, while spreadsheets are helpful, they have limitations, such as collaborating problems, establishing a transparent versioning control system, and formatting issues, that could affect the execution of the dataLayer.
For a more scalable and structured approach, you can consider using project management tools like Jira or documentation platforms like Notion. These tools offer a better user experience, improved organization, and seamless sharing capabilities.
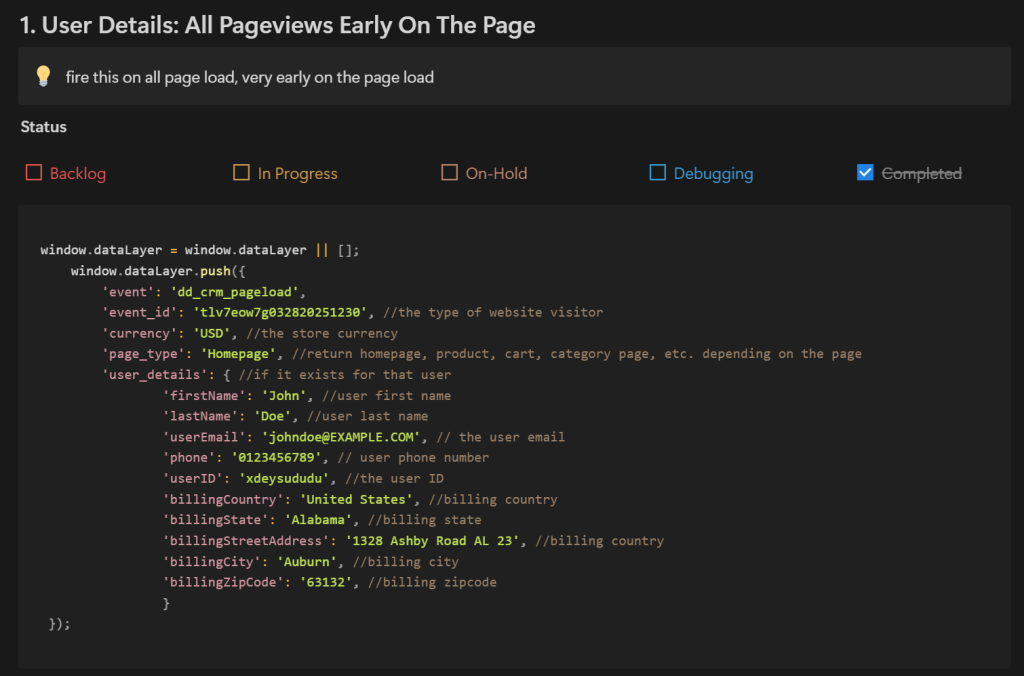
I use them and recommend integrating them into your workflow.
There are other options in the market that you can explore, too.
Using an Internal Naming Convention (e.g., a recognized prefix for event names)
Have you ever noticed that all native GTM events have a “gtm.” prefix?
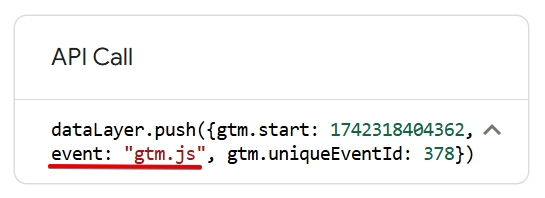
This prefix helps Google Tag Manager identify its own dataLayer events, preventing confusion with events triggered by other integrations or sources.
Surprisingly, one of the most common mistakes I see data teams make is failing to apply a similar naming convention to their own custom dataLayer events.
Using a unique prefix for your dataLayer event names is crucial. It allows your team to distinguish internally created events from those triggered by third-party integrations on your website or sources.
For example, when debugging, you might come across a dataLayer push like this:
<script>
window.dataLayer = window.dataLayer || [];
window.dataLayer.push({
'event': 'page_load',
'loggedInStatus': 'logged out',
'pageProperty': {
'pageType': 'blog post',
'pageID': 'p2345',
'pageTitle': 'digital marketing role'
}
});
</script>Without any explicit identifier, how can you tell whether the dataLayer event was manually implemented or automatically generated by an external integration?
By applying a prefix to the event name, you provide immediate clarity, as I have done in the code below. Helping me understand that it’s a DumbData created dataLayer push.
<script>
window.dataLayer = window.dataLayer || [];
window.dataLayer.push({
'event': 'dd_page_load',
'loggedInStatus': 'logged out',
'pageProperty': {
'pageType': 'blog post',
'pageID': 'p2345',
'pageTitle': 'digital marketing role'
}
});
</script>When standardizing dataLayer event names using prefixes for better organization, It’s not enough to simply add a prefix.
You should also communicate this structure internally so that analysts, developers, and external teams can recognize which dataLayer events were manually created by your organization.
Doing this ensures that any necessary adjustments or troubleshooting can be handled efficiently.
Some examples of useful prefix conventions include:
- int_<event name> → “int” stands for internal
- dd_<event name> → “dd” could represent a company abbreviation, such as DumbData
For even more transparency, consider adding a dataLayer key in the dataLayer structure called “implementation_source“, specifying how the event was deployed (e.g., hard-coded, via Google Tag Manager, or through another method).
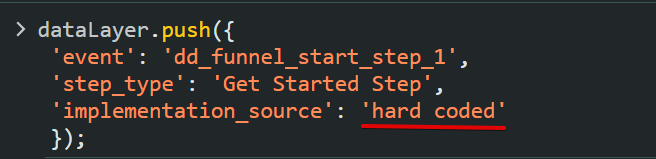
Here is an example of a dataLayer initiated from Google Tag Manager.
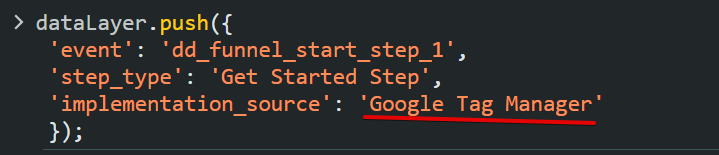
You may also choose to use a suffix if it aligns with your organization’s or personal preferences.
Speaking of event names, this brings us to another critical aspect of dataLayer governance: ensuring that every dataLayer push includes an event name.
Ensuring Every DataLayer Push Includes an Event Name
Imagine trying to trigger a tag on a dataLayer event execution for a user action, only to find a vague entry labeled “message” in Google Tag Manager’s preview mode.

This happens when a dataLayer push does not include an event name, meaning the “event” key is missing from the code.
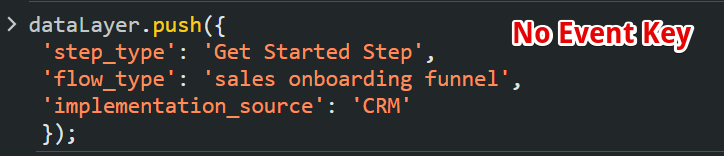
Working with dataLayer pushes that lack event names can make implementation unnecessarily complex. This is why dataLayer governance best practices should require every dataLayer push to include a clear event name.
So Why Do Event Names Matter?
- Event names help categorize user interactions, making it easier to create triggers in GTM.
- A missing event name can cause difficulties in tracking and debugging.
- It ensures consistency in data collection and analysis.
Best Practices for Event Naming
- Use unique event names based on the user action.
- Example: You shouldn’t use the same event name for both a form submission and a popup interaction, unless there’s a clear reason for doing so.
- Balance consistency and flexibility: in some cases, the same event name might apply to different actions, but this should be where your thinking hat comes on.
- Standardize the naming format, for example, using lowercase and snake_case format, camelCase, PascalCase, uppercase format, etc.
Personally, I recommend avoiding standard sentence formatting with spaces, such as “Add To Cart,” or ending the dataLayer event name with a period or any special character.
Use the Right Tools for Sharing DataLayer Code
As mentioned earlier, spreadsheets have limitations when it comes to sharing dataLayer code.
One key issue is formatting errors, as JavaScript code may become misformatted, and this error can propagate when someone copies and pastes it for implementation.
This is especially problematic during the planning stage, as incorrect formatting can lead to implementation failures later on.
Here are Best Practices for Sharing DataLayer Code
- Use spreadsheets for only documentation (if you must), not for direct code sharing.
- Share implementation-ready code using a proper code-sharing tool to avoid formatting issues.
- If using tools like Jira, Notion, or other project management platforms, leverage their code-friendly features to ensure formatting remains intact. These tools allow for clean code sharing and copying, too, without affecting the format and functionality.
- You could also use the good old Notepad to share dataLayer codes.
Initializing The DataLayer Correctly, Especially for Page-Load Events
Many people overlook this, but if a dataLayer push is executed on page load (especially early on), such as when a user lands on a conversion success page, it’s crucial to initialize the dataLayer array beforehand.
You might want to ask why initialization is needed.
If you trigger a dataLayer event before the Google Tag Manager (GTM) container fully loads, the event push might not be successful and usable inside GTM because of the global window.dataLayer object doesn’t exist yet in the user’s browser. As a result, your tracking might fail.
To ensure dataLayer is always available, include the following line before any dataLayer.push() calls:
window.dataLayer = window.dataLayer || [];And what does this code do?
This simple yet essential JavaScript snippet ensures that the dataLayer array always exists by following these steps:
- Check if dataLayer Exists:
- window.dataLayer || [] verifies whether window.dataLayer is already defined.
- If dataLayer exists, it remains unchanged.
- If dataLayer is not defined, it initializes a new, empty array ([]).
- Assign the Correct Value to dataLayer:
- It sets window.dataLayer to either the existing dataLayer or a new empty array.
- This guarantees that dataLayer is always an array that is ready to hold measurement data.
Doing this can be crucial if your implementation is in GTM because Google Tag Manager relies on dataLayer to store and process tracking data. If dataLayer isn’t properly initialized, early page-load events might never reach GTM, leading to measurement issues and data collection failures.
So, the best practice when working with dataLayers executed early on the page load will always be to initialize dataLayer using the window.dataLayer = window.dataLayer || []; is the recommended approach because it:
- Works in the global scope, making it safe for all implementations.
- Prevents tracking failures caused by a missing dataLayer object.
- Ensures dataLayer is always available before GTM loads.
Maintaining Consistency in Structure, Key Names, and Values
Consistency is a crucial aspect of dataLayer governance, and it cuts across various elements of a dataLayer code, such as structure, key names, and values.
Ensuring uniformity across these components prevents data quality issues and maintains the reliability of your analytics.
Example of Inconsistency in Key Names
A fundamental rule of consistency is to avoid changing key names unnecessarily. For example, consider a scenario where your dataLayer uses the key step_type in a dataLayer event executed on the onboarding funnel step 1:

If another dataLayer event for the funnel step 2 unexpectedly changes the key name to funnel_step, as shown below:

This inconsistency can break data collection or cause complexity in your implementation and introduce reporting issues, leading to inaccurate analytics.
Example of Inconsistency in Data Structure
Another example of inconsistency can be seen in the Google Analytics (deprecated Universal Analytics) eCommerce dataLayer version, which was resolved in the current Google Analytics 4 (GA4) eCommerce tracking.
GA4 introduced a standardized structure where product information (item object) is always nested under the “ecommerce.items” array.

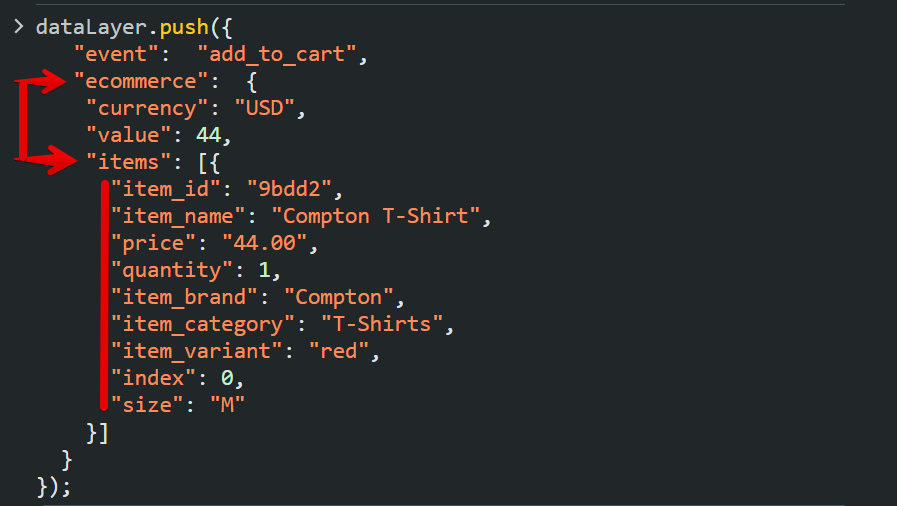
This contrasts with Universal Analytics (UA), where different events require different dataLayer structures and dot notation to access the product object, for example, “ecommerce.add.products” for Add to Cart events. This lack of uniformity required extra configuration in GTM.

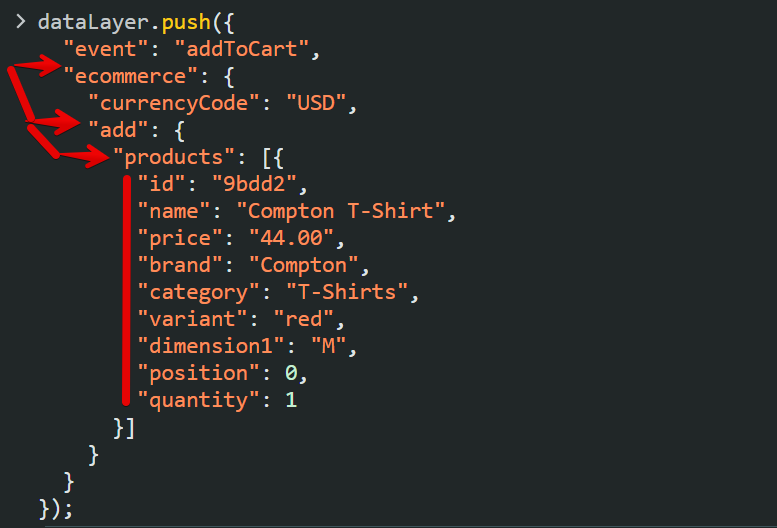
GA4 has adopted simplified eCommerce tracking by maintaining a consistent structure, ensuring that all events reference product data using the same key path.
Example of Inconsistency in Key Values
Inconsistency in DataLayer key values can occur when a specific key, such as pageType, has different values across similar pages.
For example, if one product page assigns “product” as the value while another uses “item”, this inconsistency can lead to discrepancies in your measurement tools. Such variations introduce errors at the data collection stage, ultimately affecting the accuracy and reliability of your reports.

There are many aspects of inconsistency worth discussing, but to keep this article concise, the key takeaway is this: Maintaining consistency in event names, keys, structure, and values is essential to prevent dataLayer issues that could lead to data collection errors and compromise the quality of your analytics.
Regularly Reviewing and Auditing your DataLayer Setup
An essential part of DataLayer governance and measurement strategy is conducting regular audits and revisions.
Ideally, it should be done annually or every two years, just like you would audit your Google Analytics (GA4) setup.
Having proper audit documentation is key for this process, as it provides a reference point for anyone reviewing or updating the implementation.
What to Look for During a DataLayer Audit
Here are key areas to evaluate during a DataLayer review:
- Relevance to The Current Measurement Needs & Business Goals
- Does the current DataLayer capture all necessary data for analytics and reporting?
- Are any critical data points missing?
- Is the structure aligned with the latest analytics and data collection strategies and best practices?
- Compatibility with Analytics Setup
- Does the DataLayer structure align with your analytics platforms?
- For example, if you’re still using a UA-style eCommerce DataLayer, it may work for GA4, Piwik Pro, and ad platforms like Meta, TikTok, and Microsoft Ads, but it could introduce complexities when transitioning to GA4’s recommended format.
- Privacy Compliance
- Does the DataLayer adhere to privacy regulations (e.g., GDPR, CCPA, HIPAA)?
- Are personally identifiable information (PII) or sensitive data being captured improperly?
- Consistency in Naming and Structure
- Are event names, key names, and values consistent across all DataLayer pushes?
- Have there been any unintended changes that could impact data collection?
- Execution Issues
- Are there instances where the DataLayer fails to fire when a visitor completes an action?
- Are there missing keys or incorrect data outputs that could affect tracking accuracy?
- Is the dataLayer properly initialized, as I have covered?
- Is there an occurrence of dataLayer bloat? (I’ll be covering this shortly)
- Data Formatting
- Are numeric values stored as numbers instead of strings?
- Are dates and timestamps formatted correctly?
- Ensure the dataLayer code has no formatting errors
To simplify the audit process, I have created a DataLayer Audit Worksheet specifically for Google Analytics eCommerce DataLayer audits, which you can access for free.
Properly Grouping Related Data for Better Organization
One of the key benefits of properly grouping related keys in your DataLayer is the improved organization and clarity it brings.
A well-structured DataLayer simplifies debugging, making it easier to reference keys within their appropriate categories.
For example, user-related data such as email, first name, last name, and other first-party data can be grouped under user_data_properties, as shown below:
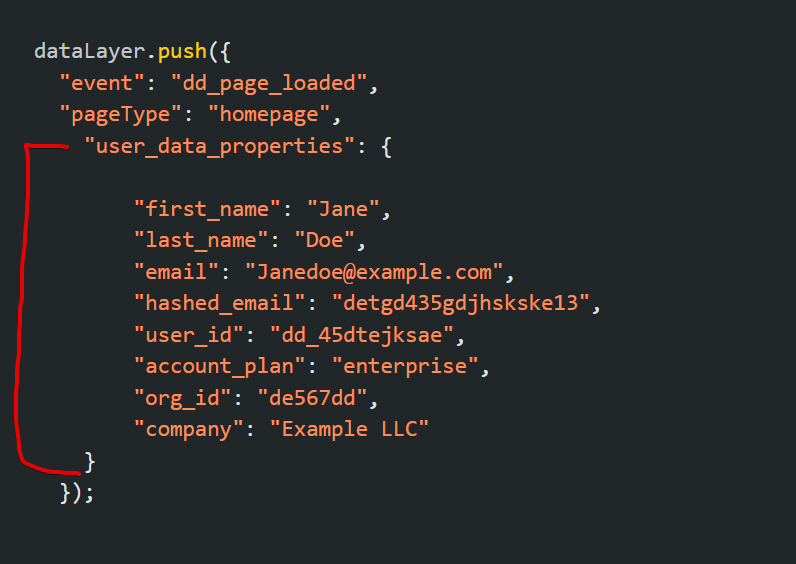
Applying this approach ensures better structure and enhances readability when managing your DataLayer implementation.
This method can be adapted in various ways to optimize your dataLayer code organization while keeping the setup simple.
In my previous projects, I have used this strategy, and it has significantly improved the clarity and consistency of DataLayer events triggered in users’ browsers.
Conducting QA Testing Before Deployment
Always QA before going live, and this is why you should do a thorough quality assurance (QA), which is crucial both before and after implementing your DataLayer code.
Skipping this step can lead to missing mistakes that can cause data inconsistencies, tracking failures, and reporting problems.
The DumbData Resource Hub also has a free DataLayer QA checklist to copy and use for your next dataLayer QA process.
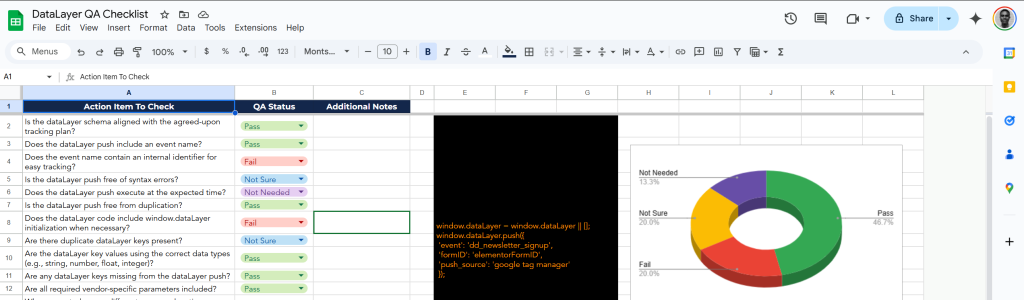
If you don’t want to use it and you’re wondering what to check for during DataLayer validation, here’s a breakdown:
Pre-Implementation QA Checklist
Before deploying your DataLayer code, ensure you check the following:
- Correct data formats for values (e.g., numbers as integers, dates in proper format).
- Consistency in keys & values (e.g., using a standard naming convention across pages).
- Proper syntax (avoiding JavaScript errors that could break execution).
- Adherence to privacy compliance (ensuring that highly sensitive data is not exposed and privacy guidelines aren’t violated).
- Correct event execution (verifying that events fire in the correct order).
- DataLayer initialization (ensuring window.dataLayer = window.dataLayer || []; is correctly placed).
Post-Implementation QA Checklist
Once the DataLayer is live, check for the following:
- Duplicate DataLayer pushes (multiple instances of the same event firing).
- Event execution failures (ensuring events trigger as expected in GTM Preview Mode).
- Missing or incorrect key-value pairs (validating that data is captured as intended).
- Cross-browser and device testing (confirming functionality across different browser types).
- Real-time validation in reporting tools (such as the debug mode in your tag debugging tools).
Ongoing Monitoring: Don’t Set It and Forget It!
Your DataLayer is not a “set it and forget it” implementation. You should commit to regular audits and monitoring to ensure continued accuracy and efficiency.
Using proactive monitoring tools can help detect tracking failures, missing keys, or broken implementations before they impact data collection.
Paid solutions like TrackingPlan, ObservePoint, and Elevar (if you run a Shopify store) provide real-time alerts for tracking issues, but there are other tools available based on your use case.
Automating DataLayer Code Generation
One effective way to minimize errors in your dataLayer implementation is to move away from manually writing the code and instead rely on automation tools if you can, but if you can’t, you could use tools to create them.
If you have extensive experience with dataLayer structures, you may choose to write them manually, especially if only a small number of implementations are needed.
However, using automation tools or tools to generate dataLayers code is far more efficient.
Why use tools instead of manual coding?
- Reduces syntax errors: Eliminates the risk of JavaScript formatting mistakes.
- Improves consistency: Ensures uniform structure across all dataLayer implementations.
- Scales efficiently: Easily generate multiple dataLayer configurations without repetitive manual work.
There are various tools available that can streamline this process and help maintain accuracy in your dataLayer setup.
You can also add AI to your dataLayer code generation process. However, its effectiveness depends on providing enough context and deeply understanding dataLayer structures.
It helps ensure you don’t end up with poorly implemented dataLayer configurations that contain errors or inconsistencies.
Keep an Eye on DataLayer Bloat
When implementing dataLayer governance for your business or clients, it’s crucial to monitor and minimize DataLayer bloat, which is the excessive occurrence/execution of dataLayer pushed on the user browser, which can negatively impact site performance and user experience.
DataLayer bloat can be the accumulation of unnecessary or redundant key-value pairs that serve no purpose.
For instance, a single dataLayer event push containing over 700 key-value pairs can lead to inefficiencies, making data processing more complex and potentially impacting site performance.
What is DataLayer Bloat?
DataLayer bloat occurs when excessive, duplicate, or irrelevant data is pushed into the dataLayer. This can lead to:
- Slower page load times due to increased JavaScript execution.
- Increased complexity, making debugging and maintenance more difficult.
- Unnecessary data is being sent to analytics tools, potentially skewing insights.
Examples of DataLayer Bloat
- Duplicate Data Pushes
- Example: The same pageView event is pushed multiple times within a single page load.
- Excessive Data Points
- Example: Including many user data points or unnecessary metadata in the key-value pairs, which are never used for any measurement.
How to Check for DataLayer Bloat
- Google Tag Manager Preview Mode –> Inspect the dataLayer pushes in real-time.
- DataLayer Checker Chrome Extension –> A browser extension to analyze and detect redundant entries.
- Browser Console –> By executing the “dataLayer” command to view the full structure of your dataLayer in the browser’s Developer Tools.
Vendor Specifications Still Matter
When creating and implementing a dataLayer on your website, it serves a specific purpose and, optionally, a destination.
- The purpose defines the action or event that triggers the dataLayer push.
- The destination determines where the collected data will be sent.
Both, in turn, influence both the data points collected at the dataLayer event execution and the format of the dataLayer push.
A key best practice in dataLayer governance is ensuring that your implementation adheres to the vendor specifications of the platform you intend to send the data to, especially if compliance is mandatory.
For example, suppose you’re setting up an eCommerce dataLayer push, and you’re only using GA4 on your website, and you will be setting up Google Analytics eCommerce tracking. In that case, you need to follow Google’s format to avoid unnecessary complexities in measurement.
Taking GA4 eCommerce tracking as another example, Google’s specifications require clearing the previous eCommerce object using:
dataLayer.push({ ecommerce: null });before pushing a new eCommerce event. This prevents outdated data from being included in subsequent dataLayer pushes.
While this approach is highly recommended when updating objects dynamically, it may not be necessary for objects that are static and not expected to change, such as user information.
Types of Vendor Specifications
Vendor specifications can take different forms, including:
- Required data formats (e.g., string, number, boolean)
- Mandatory event structures
- Key-value naming conventions
- Required clearing/reset actions before new event pushes
- Order of execution for events to ensure proper data flow
By following vendor specifications, you ensure data consistency, accuracy, and compatibility with analytics and marketing platforms, making your measurement efforts more effective.
Final Thoughts
Beyond the best governance practices discussed in this guide, defining a clear DataLayer specification in your documentation is essential.
This should include not only event names and key-value pairs but also expected data formats to maintain consistency.
Additionally, establishing a versioning system for your DataLayer implementation can be beneficial.
Version control helps track schema changes over time, making it easier to reference previous updates. While this may not be of any value for small businesses, organizations with complex dataLayer setups will find it invaluable for long-term maintenance.
You should also establish a clear mechanism for handling dataLayer keys with no assigned value when a dataLayer event is pushed.
To make your DataLayer QA process more efficient and to support better DataLayer governance, I’ve created a free DumbData checklist/worksheet, which you can access here.
Ensuring DataLayer quality should be a top priority in your implementations. Beyond the best practices already covered in this article, here are a few additional checks to consider:
- Should the DataLayer push trigger on a page reload?
- This is especially relevant for purchase tracking and other events, like transactions, that should fire only once per action.
- Is the previous DataLayer object cleared before pushing an updated version?
- This is a needed practice in GA4 eCommerce tracking to prevent duplicate or outdated data from carrying over.
- If an object is expected to change frequently during a user session (e.g., cart contents), it’s a good idea to clear it before pushing updated values.
- However, clearing the object is unnecessary for static object data that doesn’t change often (e.g., user information).
By following all the above and the governance checks and strategies covered in this guide, you’ll be able to establish a strong DataLayer governance framework that enhances the quality of your measurements for your business or clients.
If you need guidance on implementation, troubleshooting DataLayer issues, or optimizing your analytics setup, feel free to reach out with your questions.
Until then, happy measuring!